
Node.js Axios/CheerioJS Beginners Series Part 4: Retries and Concurrency
In Part 1 and Part 2 of this Node.js Axios/CheerioJS Beginners Series, we learned how to build a basic web scraper and extract data from websites, as well as how to clean the scraped data. Then in Part 3 we learned how to save the data in a variety of ways.
In Part 4, we'll explore how to make our scraper more robust and scalable by handling failed requests and using concurrency.
- Understanding Scraper Performance Bottlenecks
- Retry Requests and Concurrency Importance
- Retry Logic Mechanism
- Concurrency Management
- Complete Code
- Next Steps
Node.js Cheerio 6-Part Beginner Series
This 6-part Node.js Axios/CheerioJS Beginner Series will walk you through building a web scraping project from scratch, covering everything from creating the scraper to deployment and scheduling.
- Part 1: Basic Node.js Cheerio Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
- Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
- Part 3: Storing Scraped Data - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
- Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (This article)
- Part 5: Mimicking User Behavior - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
- Part 6: Avoiding Detection with Proxies - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
The code for this project is available on Github.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Understanding Scraper Performance Bottlenecks
In any web scraping project, the network delay acts as the initial bottleneck. Scraping requires sending numerous requests to a website and processing their responses.
Even though each request and response travel over the network in mere fractions of a second, these small delays accumulate and significantly impact scraping speed when many pages are involved (say, 5,000).
Although humans visiting just a few pages wouldn't notice such minor delays, scraping tools sending hundreds or thousands of requests can face delays that stretch into hours. Furthermore, network delay is just one-factor impacting scraping speed.
The scraper does not only send and receive requests, but also parses the extracted data, identifies the relevant information, and potentially stores or processes it. While network delays may be minimal, these additional steps are CPU-intensive and can significantly slow down scraping.
Retry Requests and Concurrency Importance
When web scraping, retrying requests, and using concurrency are important for several reasons. Retrying requests helps handle temporary network glitches, server errors, rate limits, or connection timeouts, increasing the chances of a successful response.
Common status codes that indicate a retry is worth trying include:
- 429: Too many requests
- 500: Internal server error
- 502: Bad gateway
- 503: Service unavailable
- 504: Gateway timeout
Websites often implement rate limits to control traffic. Retrying with delays can help you stay within these limits and avoid getting blocked. While scraping, you might encounter pages with dynamically loaded content. This may require multiple attempts and retries at intervals to retrieve all the elements.
Now let’s talk about concurrency. When you make sequential requests to websites, you make one at a time, wait for the response, and then make the next one.
In the diagram below, the blue boxes show the time when your program is actively working, while the red boxes show when it's paused waiting for an I/O operation, such as downloading data from the website, reading data from files, or writing data to files, to complete.

Source: Real Python
However, concurrency allows your program to handle multiple open requests to websites simultaneously, significantly improving performance and efficiency, particularly for time-consuming tasks.
By concurrently sending these requests, your program overlaps the waiting times for responses, reducing the overall waiting time and getting the final results faster.
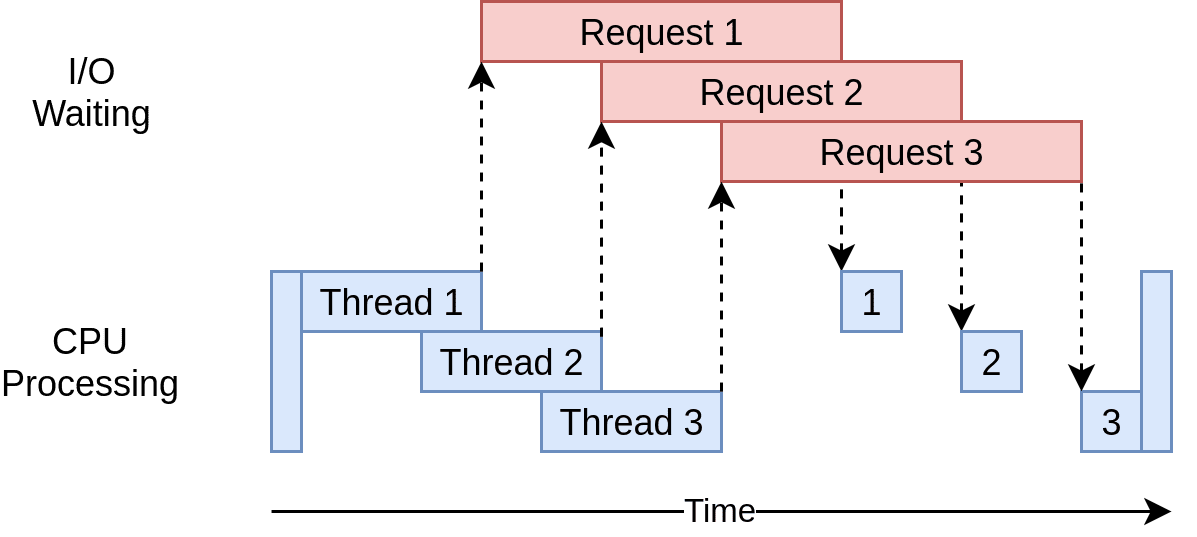 Source: Real Python
Source: Real Python
Retry Logic Mechanism
Let's examine how we'll implement retry login functionality within our scraper. Please review the scrape function from the previous parts of this series where we iterated through a list of URLs, made requests to them, and checked for a 200 status code.
for (const url of listOfUrls) {
const response = await axios.get(url);
if (response.status == 200) {
// ...
}
}
To implement the retry mechanism, we’ll first call a new makeRequest method. Then, we'll check that that a response was actually returned
const response = await makeRequest(url, 3, false);
if (!response) {
throw new Error(`Failed to fetch ${url}`);
}
The makeRequest method takes an argument for URL, number of retries, and whether or not to check for a bot response. This method then loops for the number of retries. If the request succeeds within that number, the response is returned. Otherwise we continue trying until we are out of retries and then return null.
async function makeRequest(url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
const response = await axios.get(url);
if ([200, 404].includes(response.status)) {
if (antiBotCheck && response.status == 200) {
if (response.data.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
If the anti-bot check is set to true and a valid status code is returned, the code performs some rudimentary checks to make sure the returned page is not a page for bots. With that, our method is completely ready to handle retry requests and bot checks.
Concurrency Management
Concurrency refers to the ability to execute multiple tasks or processes concurrently. Concurrency enables efficient utilization of system resources and can often speed up program execution.
In NodeJS, concurrency looks a bit different from traditional multi-threaded or multi-process concurrency due to its single-threaded event-driven architecture.
Node.js operates on a single thread, using non-blocking I/O calls, allowing it to support tens of thousands of concurrent connections without incurring the cost of thread context switching.
However, for CPU-intensive tasks, NodeJS provides the worker_threads module. This module enables the use of threads that execute JavaScript in parallel. To avoid race conditions and make thread-safe calls, data is passed between threads using MessageChannel.
A popular alternative for concurrency in NodeJS is the cluster module that allows you to create multiple child processes to take advantage of multi-core systems. We will use worker_threads in this guide because it is more suited to the work.
Here is what our entrypoint code looks like to now support worker_threads:
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url },
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
// Perform work
const { startUrl } = workerData;
const handleWork = async (workUrl) => {
const { nextUrl, products } = await scrape(workUrl);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
This may look complicated compared to threading in languages like Python, but it is simple to understand.
- We first have to use
isMainThreadto determine if the code is being executed in the main thread or a worker thread. - If it is the main thread, we perform the logic to start worker threads. We create a promise for each worker thread so that we can wait for them to finish from our main thread.
- We assign a URL from the
listOfUrlsto each worker as astartUrl. Then we set up some event listeners. - The worker threads will use the
messageevent to send back products it found, so we add them to the pipeline then. If the worker thread has an error, we just call our promise reject. - Lastly when the worker thread exits successfully, we call out promise resolve.
- Once we've created all these workers and added them to an array, we wait for all promises in the array to to complete.
- If the code is running in a worker thread instead, we grab the
startUrlfromworkerDatathen we define ahandleWorkfunction so we can use async/await and recursion. - The
handleWorkfunction scrapes the url and posts all products found to theMessageChannel(parentPort). - Afterwards, if another page URL was found, we recursively scrape it as well to repeat the same process.
Complete Code
With all that work done, our scraper has become more scalable and robust. It is now better equipped to handle errors and perform concurrent requests.
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
const {
Worker,
isMainThread,
parentPort,
workerData,
} = require("worker_threads");
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function makeRequest(url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
const response = await axios.get(url);
if ([200, 404].includes(response.status)) {
if (antiBotCheck && response.status == 200) {
if (response.data.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
async function scrape(url) {
const response = await makeRequest(url, 3, false);
if (!response) {
throw new Error(`Failed to fetch ${url}`);
}
const html = response.data;
const $ = cheerio.load(html);
const productItems = $("product-item");
const products = [];
for (const productItem of productItems) {
const title = $(productItem).find(".product-item-meta__title").text();
const price = $(productItem).find(".price").first().text();
const url = $(productItem).find(".product-item-meta__title").attr("href");
products.push({ name: title, price: price, url: url });
}
const nextPage = $("a[rel='next']").attr("href");
return {
nextUrl: nextPage ? "https://www.chocolate.co.uk" + nextPage : null,
products: products,
};
}
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url },
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
// Perform work
const { startUrl } = workerData;
const handleWork = async (workUrl) => {
const { nextUrl, products } = await scrape(workUrl);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
Next Steps
We hope you now have a good understanding of why you need to retry requests and use concurrency when web scraping. This includes how the retry logic works, how to check for anti-bots, and how the concurrency management works.
If you would like the code from this example please check out on Github here!
The next tutorial covers how to make our spider production-ready by managing our user agents and IPs to avoid getting blocked. (Part 5)