
Node.js Axios/CheerioJS Beginners Series Part 3: Storing Data
In Part 1 and Part 2 of this Node.js Axios/CheerioJS Beginners Series, we learned how to build a basic web scraper and extract data from websites, as well as how to clean the scraped data.
In Part 3, we'll explore various methods for saving the data in formats suitable for common use cases. We'll cover saving data to JSON files, as well as storing the data in databases or AWS S3 buckets.
- Saving Data to a JSON File
- Saving Data to Amazon S3 Storage
- Saving Data to MySQL Database
- Saving Data to Postgres Database
- Complete Code
- Next Steps
Node.js Axios/CheerioJS 6-Part Beginner Series
This 6-part Node.js Axios/CheerioJS Beginner Series will walk you through building a web scraping project from scratch, covering everything from creating the scraper to deployment and scheduling.
- Part 1: Basic Node.js Cheerio Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
- Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
- Part 3: Storing Scraped Data - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (This article)
- Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
- Part 5: Mimicking User Behavior - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
- Part 6: Avoiding Detection with Proxies - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Coming soon)
The code for this project is available on Github.
Saving Data to a JSON File
💡Note: All methods for storing data in JSON files, databases, or S3 buckets will be implemented within the ProductDataPipeline class, which was created in Part 2 of this series.
To save data to the JSON file, we’ll create a method called saveToJson(). The method performs the following actions.
It checks if the given jsonFileName already exists, similar to our previous saveToCsv method we don't want to overwrite existing data. If the file exists, we load the content into the existingData array.
Then we use the JavaScript spread operator (...) to merge the existing data (if there is any) with the current storageQueue values.
Finally, we write that merged array to the file with the given jsonFileName.
saveToJson() {
if (this.storageQueue.length <= 0) {
return;
}
const fileExists = fs.existsSync(this.jsonFileName);
let existingData = [];
if (fileExists) {
const fileContent = fs.readFileSync(this.jsonFileName, "utf8");
existingData = JSON.parse(fileContent);
}
const mergedData = [...existingData, ...this.storageQueue];
fs.writeFileSync(this.jsonFileName, JSON.stringify(mergedData, null, 2));
}
Which produces JSON like this:

Saving Data to Amazon S3 Storage
We've already covered how to export the data to a CSV file in Part 2 of this series. Nonetheless, we've also included the code for that, which you can find in the last section. Now, let's save the created CSV file directly to an Amazon S3 bucket (you'll need to have one set up already).
If you don't have a bucket yet, you can follow the instructions on how to set one up.
Once you've made a bucket, start by installing the @aws-sdk/client-s3 package to use AWS S3 from Node.js.
npm i @aws-sdk/client-s3
To get started, set up the necessary credentials to connect to Amazon S3. With these, the method creates an S3 client using the library we just installed. Then we ensure that the CSV file exists, this is because our program can execute quite quickly and due to Node's asynchronous nature we want to make sure the file has been written before trying to upload it. Then we send a PutObjectCommand with the bucket name, key and content of the CSV file.
Within the bucket, the Key serves as the file name that would be used in the Amazon S3. The data to be uploaded is defined in the Body parameter.
async saveToS3Bucket() {
const client = new S3Client({
region: "us-east-1",
credentials: {
accessKeyId: "YOUR_ACCESS_KEY_ID",
secretAccessKey: "YOUR_SECRET_ACCESS_KEY",
},
});
let retry = 3;
while (retry > 0) {
if (!fs.existsSync(this.csvFilename)) {
await new Promise((resolve) => setTimeout(resolve, 1000));
}
retry -= 1;
}
const params = {
Bucket: this.s3Bucket,
Key: this.csvFilename,
Body: fs.createReadStream(this.csvFilename),
};
await client.send(new PutObjectCommand(params));
}
Of course, you'll need to change YOUR_ACCESS_KEY_ID and YOUR_SECRET_ACCESS_KEY to be your own credentials. As well, make sure a bucket with the given name exists.
Here’s a snapshot showing that the file has been uploaded successfully:
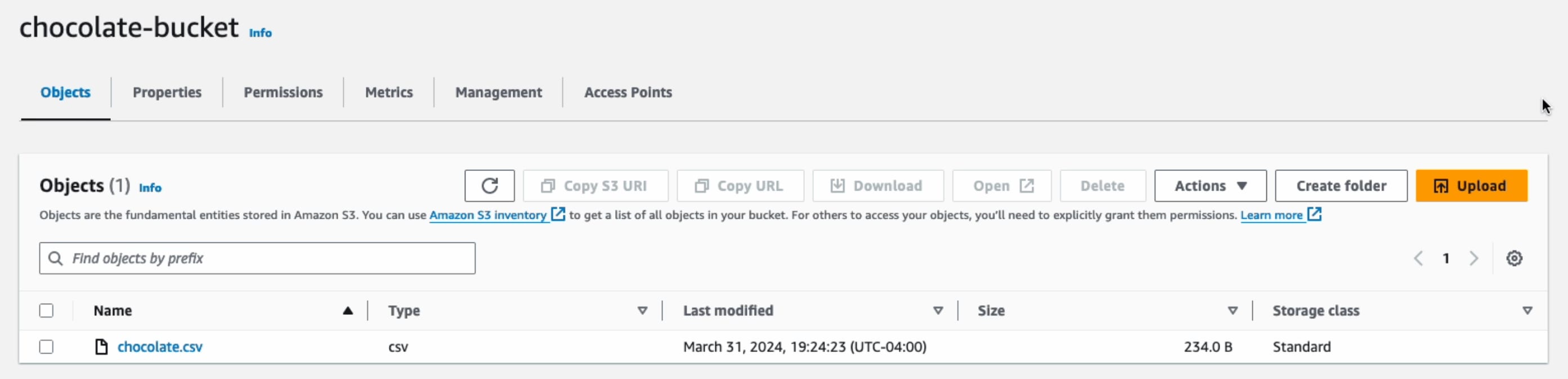
Note: When saving data to AWS S3, employ delayed file uploads. This means that the file is first temporarily saved locally on the machine running the scraper, and then uploaded to AWS S3 once the scraper's job is complete.
Saving Data to MySQL Database
Here, we'll show you how to save data to MySQL databases. To follow along, we assume you already have a database named chocolate_db set up.
Downloading MySQL
For setting up a MySQL database, check out the following resources:
Creating MySQL Table��
We assume you already have a database set up and a table called chocolate_products in your database. If not, you can log in to your database and run the following command to create the table:
CREATE TABLE IF NOT EXISTS chocolate_products (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
price_gb VARCHAR(255),
price_usd VARCHAR(255),
url TEXT
);
Connecting Scraper To MySQL Database
The first step is to establish a connection to your MySQL database and the specific table where you'll store the scraped data. To interact with your MySQL database from Node, you'll need to install the mysql package.
npm i mysql
Then, to establish a connection, we use the createConnection and connect methods. When using createConnection we define the host, username, password and database name for our MySQL database. Then we create the INSERT query and use the connection.query method to execute it. You may have noticed, the entire operation is wrapped in a Promise return statement. This is because the mysql package unfortunately does not support async/await or Promises so our method returns its own promise to make it compatible with our other code.
if (this.storageQueue.length <= 0) {
return;
}
return new Promise((resolve, reject) => {
const connection = mysql.createConnection({
host: "localhost",
user: "root",
password: "password",
database: this.mysqlDbName,
});
connection.connect((err) => {
if (err) {
console.error("Error connecting to database: ", err);
reject(err);
return;
}
const query =
"INSERT INTO chocolate_products (name, price_gb, price_usd, url) VALUES ?";
const values = this.storageQueue.map((product) => [
product.name,
product.priceGb,
product.priceUsd,
product.url,
]);
connection.query(query, [values], (err, results) => {
if (err) {
console.error("Error inserting data into database: ", err);
connection.end();
reject(err);
} else {
connection.end();
resolve(results);
}
});
});
});
Here’s the snapshot of the data stored in the MySQL database:
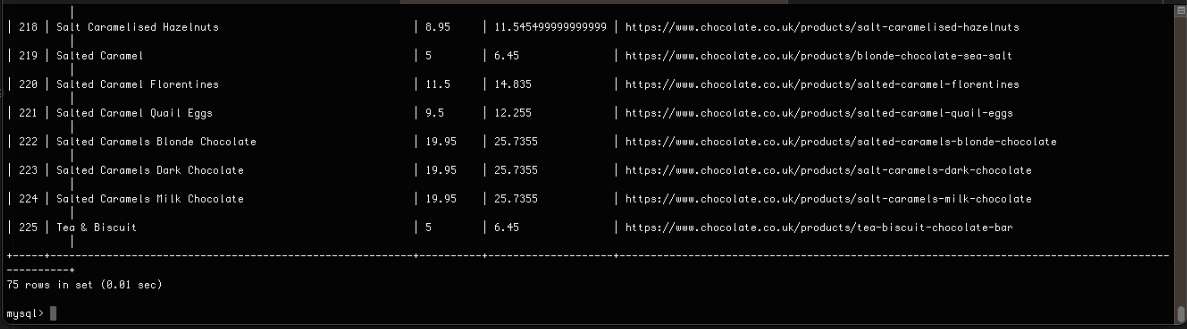
Saving Data to Postgres Database
Saving Data to Postgres Database
Here, we'll show you how to save data to Postgres databases. To follow along, we assume you already have a database named chocolate_db set up.
Downloading Postgres
For setting up a Postgres database, check out the following resources:
Creating Postgres Table
As mentioned earlier, we're assuming you’ve a Postgres database set up and a table named chocolate_products already exists in your database. If not, please log in to your Postgres database and execute the following command to create the table:
CREATE TABLE IF NOT EXISTS chocolate_products (
id SERIAL PRIMARY KEY,
name VARCHAR(255),
price_gb VARCHAR(255),
price_usd VARCHAR(255),
url TEXT
);
Connecting Scraper To Postgres Database
To save data to the Postgres database, we can use the pg package.
npm i pg
This function will look a little bit different than the MySQL function. Primarily because pg supports async/await. We create the connection using the Client object and client.connect() then we create the query string and finally we iterate through the storageQueue to execute the query for each object using client.query. We have to do this because pg does not support bulk inserts.
async saveToPostgres() {
if (this.storageQueue.length <= 0) {
return;
}
const client = new Client({
user: "postgres",
host: "localhost",
database: this.pgDbName,
password: "mysecretpassword",
port: 5432,
});
try {
await client.connect();
const query =
"INSERT INTO chocolate_products (name, price_gb, price_usd, url) VALUES ($1, $2, $3, $4)";
for (const product of this.storageQueue) {
await client.query(query, [
product.name,
product.priceGb,
product.priceUsd,
product.url,
]);
}
} catch (error) {
} finally {
await client.end();
}
}
Here’s the snapshot of the data stored in the PostgreSQL database:
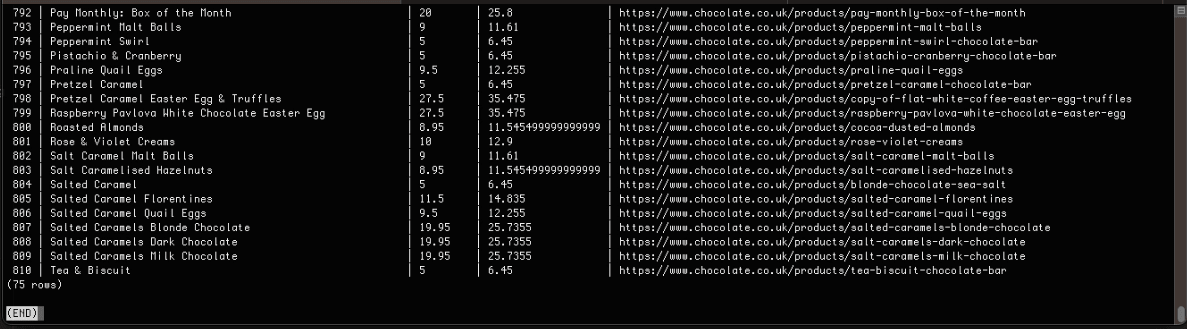
Complete Code
When you execute the code, it will create two files, chocolate.csv and chocolate.json. It will then store the data in MySQL, PostgreSQL, and the Amazon S3 bucket.
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
const { S3Client, PutObjectCommand } = require("@aws-sdk/client-s3");
const mysql = require("mysql");
const { Client } = require("pg");
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
class ProductDataPipeline {
constructor(
csvFilename = "",
jsonFileName = "",
s3Bucket = "",
mysqlDbName = "",
pgDbName = "",
storageQueueLimit = 5
) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.jsonFileName = jsonFileName;
this.s3Bucket = s3Bucket;
this.mysqlDbName = mysqlDbName;
this.pgDbName = pgDbName;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.csvFileOpen = false;
}
saveToJson() {
if (this.storageQueue.length <= 0) {
return;
}
const fileExists = fs.existsSync(this.jsonFileName);
let existingData = [];
if (fileExists) {
const fileContent = fs.readFileSync(this.jsonFileName, "utf8");
existingData = JSON.parse(fileContent);
}
const mergedData = [...existingData, ...this.storageQueue];
fs.writeFileSync(this.jsonFileName, JSON.stringify(mergedData, null, 2));
}
async saveToS3Bucket() {
const client = new S3Client({
region: "us-east-1",
credentials: {
accessKeyId: "YOUR_ACCESS_KEY_ID",
secretAccessKey: "YOUR_SECRET_ACCESS_KEY",
},
});
let retry = 3;
while (retry > 0) {
if (!fs.existsSync(this.csvFilename)) {
await new Promise((resolve) => setTimeout(resolve, 1000));
}
retry -= 1;
}
const params = {
Bucket: this.s3Bucket,
Key: this.csvFilename,
Body: fs.createReadStream(this.csvFilename),
};
await client.send(new PutObjectCommand(params));
}
saveToMysql() {
if (this.storageQueue.length <= 0) {
return;
}
return new Promise((resolve, reject) => {
const connection = mysql.createConnection({
host: "localhost",
user: "root",
password: "password",
database: this.mysqlDbName,
});
connection.connect((err) => {
if (err) {
console.error("Error connecting to database: ", err);
reject(err);
return;
}
const query =
"INSERT INTO chocolate_products (name, price_gb, price_usd, url) VALUES ?";
const values = this.storageQueue.map((product) => [
product.name,
product.priceGb,
product.priceUsd,
product.url,
]);
connection.query(query, [values], (err, results) => {
if (err) {
console.error("Error inserting data into database: ", err);
connection.end();
reject(err);
} else {
connection.end();
resolve(results);
}
});
});
});
}
async saveToPostgres() {
if (this.storageQueue.length <= 0) {
return;
}
const client = new Client({
user: "postgres",
host: "localhost",
database: this.pgDbName,
password: "mysecretpassword",
port: 5432,
});
try {
await client.connect();
const query =
"INSERT INTO chocolate_products (name, price_gb, price_usd, url) VALUES ($1, $2, $3, $4)";
for (const product of this.storageQueue) {
await client.query(query, [
product.name,
product.priceGb,
product.priceUsd,
product.url,
]);
}
} catch (error) {
} finally {
await client.end();
}
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
async addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
this.saveToJson();
await this.saveToMysql();
await this.saveToPostgres();
this.storageQueue = [];
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function scrape() {
const pipeline = new ProductDataPipeline(
"chocolate.csv",
"chocolate.json",
"chocolate-bucket",
"chocolate_db",
"chocolate_db",
5
);
for (const url of listOfUrls) {
const response = await axios.get(url);
if (response.status == 200) {
const html = response.data;
const $ = cheerio.load(html);
const productItems = $("product-item");
for (const productItem of productItems) {
const title = $(productItem).find(".product-item-meta__title").text();
const price = $(productItem).find(".price").first().text();
const url = $(productItem)
.find(".product-item-meta__title")
.attr("href");
await pipeline.addProduct({ name: title, price: price, url: url });
}
const nextPage = $("a[rel='next']").attr("href");
if (nextPage) {
listOfUrls.push("https://www.chocolate.co.uk" + nextPage);
}
}
}
await pipeline.close();
await pipeline.saveToS3Bucket();
}
(async () => {
await scrape();
})();
Next Steps
We hope you now have a good understanding of how to save the data you've scraped into the file or database you need! If you’ve any questions leave them in the comments below and we'll do our best to help out!
If you would like the code from this example please check out on Github here!
The next tutorial covers how to make our scraper more robust and scalable by handling failed requests and using concurrency.