
Node.js Axios/CheerioJS Beginners Series Part 2: Cleaning Dirty Data & Dealing With Edge Cases
In Part 1 of this Node.js Axios/CheerioJS Beginners Series, we learned the basics of scraping with Node.js and built our first Node.js scraper.
Web data can be messy, unstructured, and have many edge cases. So, it's important that your scraper is robust and deals with messy data effectively.
So, in Part 2: Cleaning Dirty Data & Dealing With Edge Cases, we're going to show you how to make your scraper more robust and reliable.
- Strategies to Deal With Edge Cases
- Structure your scraped data with Data Classes
- Process and Store Scraped Data with Data Pipeline
- Testing Our Data Processing
- Next Steps
Node.js Axios/CheerioJS 6-Part Beginner Series
This 6-part Node.js Axios/CheerioJS Beginner Series will walk you through building a web scraping project from scratch, covering everything from creating the scraper to deployment and scheduling.
- Part 1: Basic Node.js Cheerio Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
- Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (This article)
- Part 3: Storing Scraped Data - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
- Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
- Part 5: Mimicking User Behavior - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
- Part 6: Avoiding Detection with Proxies - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Coming soon)
The code for this project is available on Github.
Strategies to Deal With Edge Cases
Web data is often messy and incomplete which makes web scraping a bit more complicated for us. For example, when scraping e-commerce sites, most products follow a specific data structure. However, sometimes, things are displayed differently:
- Some items have both a regular price and a sale price.
- Prices might include sales taxes or VAT in some cases but not others.
- If a product is sold out, its price might be missing.
- Product descriptions can vary, with some in paragraphs and others in bullet points.
Dealing with these edge cases is part of the web scraping process, so we need to come up with a way to deal with it.
In the case of the chocolate.co.uk website that we’re scraping for this series, if we inspect the data we can see a couple of issues.
Here's a snapshot of the CSV file that will be created when you scrape and store data using Part 1 of this series.
In the price section, you'll notice that some values are solely numerical (e.g. 9.95), while others combine text and numbers, such as "Sale priceFrom £2.00". This shows that the data is not properly cleaned, as the “Sale priceFrom £2.00” should be represented as 2.00.

There might be some other couple of issues such as:
- Some prices are missing, either because the item is out of stock or the price wasn't listed.
- The prices are currently shown in British Pounds (GBP), but we need them in US Dollars (USD).
- Product URLs are relative and would be preferable as absolute URLs for easier tracking and accessibility.
- Some products are listed multiple times.
There are several options to deal with situations like this:
| Options | Description |
|---|---|
| Try/Catch | You can wrap parts of your parsers in Try/Except blocks so if there is an error scraping a particular field, it will then revert to a different parser. |
| Conditional Parsing | You can have your scraper check the HTML response for particular DOM elements and use specific parsers depending on the situation. |
| Data Classes | With data classes, you can define structured data containers that lead to clearer code, reduced boilerplate, and easier manipulation. |
| Data Pipelines | With Data Pipelines, you can design a series of post-processing steps to clean, manipulate, and validate your data before storing it. |
| Clean During Data Analysis | You can parse data for every relevant field, and then later in your data analysis pipeline clean the data. |
Every strategy has its pros and cons, so it's best to familiarize yourself with all methods thoroughly. This way, you can easily choose the best option for your specific situation when you need it.
In this project, we're going to focus on using Data Classes and Data Pipelines as they are the most powerful options available in BS4 to structure and process data.
Structure your scraped data with Data Classes
In Part 1, we scraped data (name, price, and URL) and stored it directly in a dictionary without proper structuring. However, in this part, we'll use data classes to define a structured class called Product and directly pass the scraped data into its instances.
Data classes in Node.js offer a convenient way to structure and manage the scraped data effectively. It allows you to build and extend methods to more easily work with the data.
Additionally, data classes can be easily converted into various formats like JSON, CSV, and others for storage and transmission.
The following code snippet directly passes scraped data to the product data class to ensure proper structuring and management.
new Product(rawProduct.name, rawProduct.price, rawProduct.url);
Let's examine the Product data class. We pass three arguments to the constructor but we define four fields in the class.
- name: The name of the product
- priceGb and priceUsd: The integer value derived from the price string.
- url: The url of the product
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {}
cleanPrice(priceStr) {}
convertPriceToUsd(priceGb) {}
createAbsoluteUrl(url) {}
}
You'll notice in the constructor, we call a variety of methods to clean the data before setting the field values.
Using this Data Class we are going to do the following:
cleanName: Clean the name by stripping leading and trailing whitespaces.cleanPrice: Clean the price to remove the substrings like "Sale price£" and "Sale priceFrom £”.convertPriceToUsd: Convert the price from British Pounds to US Dollars.createAbsoluteUrl: Convert relative URL to absolute URL.
Clean the Price
Cleans up price strings by removing specific substrings like "Sale price£" and "Sale priceFrom £", then converting the cleaned string to a float. If a price string is empty, the price is set to 0.0.
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
}
Convert the Price
The prices scraped from the website are in the GBP, convert GBP to USD by multiplying the scraped price by the exchange rate (1.21 in our case).
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
// Previous code...
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
}
Clean the Name
Cleans up product names by stripping leading and trailing whitespace. If a name is empty, it's set to "missing".
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
// Previous code...
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
}
Convert Relative to Absolute URL
Creates absolute URLs for products by appending their URLs to the base URL.
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
// Previous code...
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
Here's the complete code for the product data class.
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
Now, let's test our Product data class:
const p = new Product(
"Lovely Chocolate",
"Sale priceFrom £1.50",
"/products/100-dark-hot-chocolate-flake"
);
console.log(p);
Outputs:
Product {
name: 'Lovely Chocolate',
priceGb: 1.5,
priceUsd: 1.935,
url: 'https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flake'
}
This is how data classes are helping us to easily structure and manage our messy scraped data. They are properly checking edge cases and replacing unnecessary text. This cleaned data will then be returned to the data pipeline for further processing.
Here’s the snapshot of what the data that will be returned from the product data class looks like. It consists of name, priceGb, priceUsd, and url

Process and Store Scraped Data with Data Pipeline
Now that we’ve our clean data, we'll use Data Pipelines to process this data before saving it. The data pipeline will help us to pass the data from various pipelines for processing and finally store it in a csv file.
Using Data Pipelines we’re going to do the following:
- Check if an Item is a duplicate and drop it if it's a duplicate.
- Add the process data to the storage queue.
- Save the processed data periodically to the CSV file.
Let's first examine the ProductDataPipeline class and its constructor.
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
this.csvFileOpen = false;
}
saveToCsv() {}
cleanRawProduct(rawProduct) {}
isDuplicateProduct(product) {}
addProduct(rawProduct) {}
async close() {}
}
Here we define six methods in this ProductDataPipeline class:
constructor: Initializes the product data pipeline with parameters like CSV filename and storage queue limit.saveToCsv: Periodically saves the products stored in the pipeline to a CSV file.cleanRawProduct: Cleans scraped data and returns a Product object.isDuplicate: Checks if a product is a duplicate based on its name.addProduct: Adds a product to the pipeline after cleaning and checks for duplicates before storing, and triggers saving to CSV if necessary.close: Makes sure any queued data is written and closes the data pipeline.
Within the constructor, five variables are defined, each serving a distinct purpose:
seenProducts: This set is used for checking duplicates.storageQueue: This queue holds products temporarily until a specified storage limit is reached.storageQueueLimit: This variable defines the maximum number of products that can reside in thestorageQueue.csvFilename: This variable stores the name of the CSV file used for product data storage.csvFileOpen: This boolean variable tracks whether the CSV file is currently open or closed.
Add the Product
To add product details, we first clean them with the cleanRawProduct function. This sends the scraped data to the Product class, which cleans and organizes it and then returns a Product object holding all the relevant data. We then double-check for duplicates with the isDuplicate method. If it's new, we add it to a storage queue.
This queue acts like a temporary holding bin, but once it reaches its limit (five items in this case) and no CSV file is open, we'll call the saveToCsv function. This saves the first five items from the queue to a CSV file, emptying the queue in the process.
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
Check for Duplicate Product
This method checks for duplicate product names. If a product with the same name has already been encountered, it prints a message and returns true to indicate a duplicate. If the name is not found in the list of seen names, it adds the name to the list and returns false to indicate a unique product.
class ProductDataPipeline {
// Previous code...
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
}
Periodically Save Data to CSV
Now, when the storageQueueLimit reaches 5 (its maximum), the saveToCsv() function is called. The csvFileOpen variable is set to true to indicate that CSV file operations are underway. All data is extracted from the queue, appended to the storageQueue list, and the queue is then cleared for subsequent data storage.
A check is performed to determine whether the CSV file already exists. If it does not, the keys are written as headers first. Otherwise, if the file does exist, the headers are not written again, and only the data is appended using the file.write.
Then, a loop iterates through the storageQueue list, writing each product's data to the CSV file. We use template literals. Once all data has been written, the csvFileOpen variable is set to false to indicate that CSV file operations have concluded.
class ProductDataPipeline {
// Previous code...
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
}
Wait, you may have noticed that we're storing data in a CSV file periodically instead of waiting for the entire scraping script to finish.
We've implemented a queue-based approach to manage data efficiently and save it to the CSV file at appropriate intervals. Once the queue reaches its limit, the data is written to the CSV file.
This way, if the script encounters errors, crashes, or experiences interruptions, only the most recent batch of data is lost, not the entire dataset. This ultimately improves overall processing speed.
Full Data Pipeline Code
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
Let's test our ProductDataPipeline class:
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
// Add to data pipeline
pipeline.addProduct({
name: "Lovely Chocolate",
price: "Sale priceFrom £1.50",
url: "/products/100-dark-hot-chocolate-flakes",
});
// Add to data pipeline
pipeline.addProduct({
name: "My Nice Chocolate",
price: "Sale priceFrom £4",
url: "/products/nice-chocolate-flakes",
});
// Add to duplicate data pipeline
pipeline.addProduct({
name: "Lovely Chocolate",
price: "Sale priceFrom £1.50",
url: "/products/100-dark-hot-chocolate-flakes",
});
// Close pipeline when finished - saves data to CSV
pipeline.close();
Here we:
- Initialize The Data Pipeline: Creates an instance of ProductDataPipeline with a specified CSV filename.
- Add To Data Pipeline: Adds three products to the data pipeline, each with a name, price, and URL. Two products are unique and one is a duplicate product.
- Close Pipeline When Finished - Saves Data To CSV: Closes the pipeline, ensuring all pending data is saved to the CSV file.
CSV file output:
name,priceGb,priceUsd,url
Lovely Chocolate,1.5,1.935,https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flakes
My Nice Chocolate,4,5.16,https://www.chocolate.co.uk/products/nice-chocolate-flakes
Testing Our Data Processing
When we run our code, we should see all the chocolates, being crawled with the price now displaying in both GBP and USD. The relative URL is converted to an absolute URL after our Data Class has cleaned the data. The data pipeline has dropped any duplicates and saved the data to the CSV file.
Here’s the snapshot of the completely cleaned and structured data:
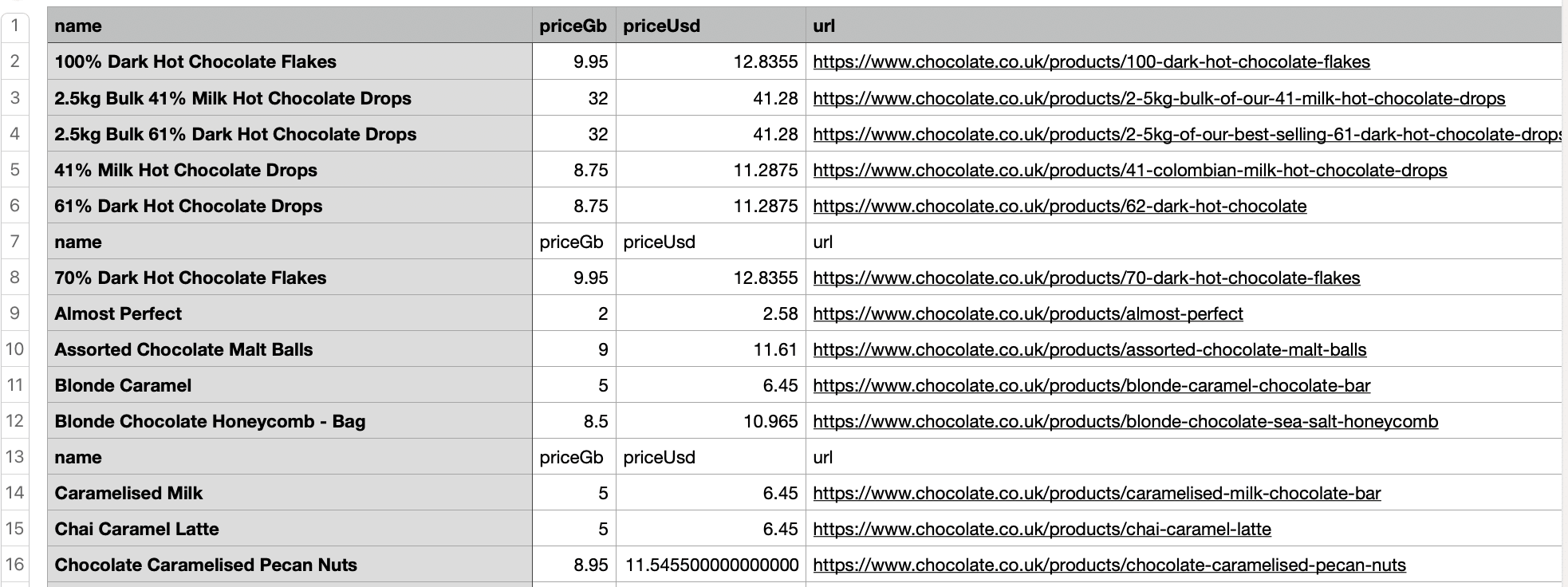
Here is the full code with the Product Dataclass and the Data Pipeline integrated:
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function scrape() {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
for (const url of listOfUrls) {
const response = await axios.get(url);
if (response.status == 200) {
const html = response.data;
const $ = cheerio.load(html);
const productItems = $("product-item");
for (const productItem of productItems) {
const title = $(productItem).find(".product-item-meta__title").text();
const price = $(productItem).find(".price").first().text();
const url = $(productItem)
.find(".product-item-meta__title")
.attr("href");
pipeline.addProduct({ name: title, price: price, url: url });
}
const nextPage = $("a[rel='next']").attr("href");
if (nextPage) {
listOfUrls.push("https://www.chocolate.co.uk" + nextPage);
}
}
}
await pipeline.close();
}
(async () => {
await scrape();
})();
Next Steps
We hope you've gained a solid understanding of the basics of data classes, data pipelines, and periodic data storage in CSV files. If you've any questions, please leave them in the comments below, and we'll do our best to assist you!
If you would like the code from this example please check out on Github here!
In (Part 3) of the series, we'll work on Storing Our Data. There are many different ways we can store the data that we scrape from databases, CSV files to JSON format, and S3 buckets.
We'll explore several different ways we can store the data and talk about their pros, and cons and in which situations you would use them.